在血液学、造血干细胞移植与细胞治疗领域,人工智能(AI)已从概念探索步入深度应用的关键阶段。2026年EBMT年会设立全体会议专题探讨AI如何塑造本学科的临床研究与实践,标志着AI应用已从分散的探索走向体系化、前沿化的学科建设。本次P01专场中,汇聚了来自诊断、数据科学、细胞治疗及工程学领域的国际顶尖专家,他们通过一系列前沿研究与转化实践,系统展示了AI在诊断精准化、临床试验设计革新、细胞治疗监测预测以及多模态数据整合等方面的突破性进展,不仅呈现了当前的技术图景,更深入探讨了AI工具融入临床常规所面临的验证、监管与培训等核心挑战,为学科迈向AI驱动的新时代指明了方向。《血液时讯》特梳理专场精粹,以飨读者。
01
AI驱动的血液学诊断:从细胞形态到基因组学的全面赋能

来自德国慕尼黑的Claudia Haferlach博士首先系统阐述了AI在血液学诊断中的机遇与现状。她指出,AI的核心价值在于提升诊断的准确性、可重复性与效率,并助力发现新知识。在细胞形态学领域,AI辅助的外周血涂片分类计数设备已有多款获得FDA或CE认证,但骨髓分析因细胞密度高、类别多而更具挑战,目前所有设备均定位为辅助角色,需资深人员监督。她通过研究实例剖析了当前模型的局限,如区分不同细胞“金标准”的生物学难题,以及因训练数据不足导致的异常细胞分类准确率低下。
在流式细胞术领域,AI应用更为广泛,涵盖质量控制、自动设门、疾病分类及微小残留病(MRD)监测。Haferlach博士展示的研究表明,全自动MRD检测系统在速度(秒级 vs. 手动30分钟以上)、可重复性及预后阈值确定上展现出显著优势。在细胞遗传学与分子遗传学领域,AI已不可或缺。AI核型分析可将分析时间从人工操作缩短至约20秒,极大提升效率并增加可分析的分裂相数量,提高小亚克隆检测敏感性。而在RNA测序、全基因组测序及多组学整合分析中,AI是处理海量高维数据的唯一可行工具,已广泛应用于疾病分类(如MDS分子分型)及疗效预测。
然而,目前真正进入临床常规的AI模型寥寥无几。Haferlach博士总结了多重挑战:数据方面,高质量、大规模的数字化数据集建设仍需努力;信任与责任方面,AI决策的可解释性及错误责任界定尚不明晰;监管与评估方面,需建立稳健的评估参数体系并加强前瞻性验证。她强调,成功的临床转化需明确临床问题、定义可接受的性能标准、确定可靠的“金标准”,并规划好实施与维护的基础设施。未来,AI将与临床医生形成协作关系,承担重复性任务,而人类专家保留最终核实与决策的责任。
02
合成数据生成:破解真实世界数据瓶颈的新路径
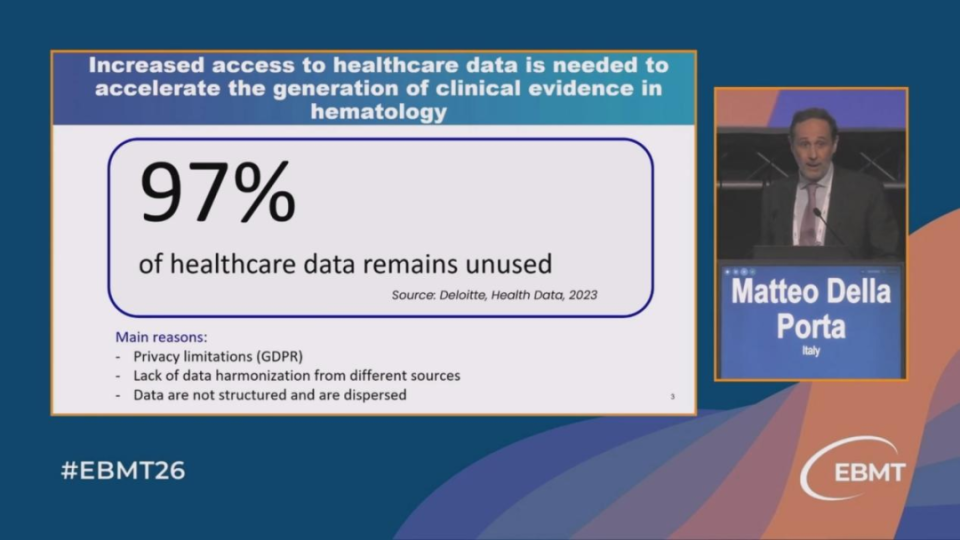
米兰Humanitas研究医院的Matteo Della Porta博士聚焦于如何利用AI技术生成“合成数据”,以解决临床研究中高质量真实世界数据稀缺与隐私受限的矛盾。合成数据是通过算法学习真实数据集的统计与临床特征后生成的人造数据,因其不对应真实患者,可规避隐私法规限制,从而实现自由共享与分析。
Della Porta博士展示了在骨髓增生异常综合征(MDS)等异质性疾病中,合成患者队列能够高度复现真实队列的基因组病变分布、染色体异常共存/互斥模式以及个体疾病自然史。为验证合成数据的可靠性,其团队开发了SAFE评估框架,通过百余项统计测试,系统评估合成数据对真实数据统计属性的概括能力、临床效用及隐私保护性。
此外,合成数据的应用前景广阔:一是加速科学证据产生,例如为极罕见疾病(如CMML)的临床决策支持系统提供外部验证所需的合成患者队列;二是革新临床试验设计,特别是在招募困难或存在伦理困境的罕见病、儿科疾病领域,可用合成数据构建外部对照组,支持单臂试验。他介绍了“No Placebo”等国际倡议,以及FDA、EMA在白皮书中对使用历史或合成对照的潜在认可。欧盟资助的多个联盟正致力于开发可靠、可解释的合成数据生成平台。Della Porta博士最后呼吁,推动现有数据库认证、建立技术联盟以及尽早与监管机构对话,是构建下一代临床试验生态系统的关键。
03
AI在细胞治疗中的多维应用:从监测预测到机制探索
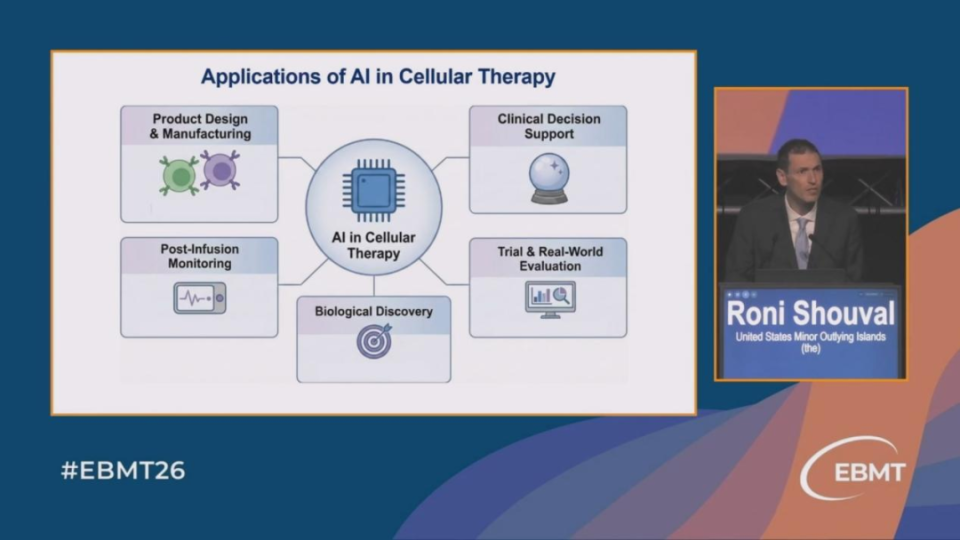
纽约纪念斯隆-凯特琳癌症中心的Roni Shouval博士分享了AI在CAR-T细胞治疗中的多个应用案例,并始终围绕“解决临床问题”这一核心。他首先介绍了“Morpho-CAR”项目:利用深度学习分析CAR-T细胞回输后外周血淋巴细胞形态变化,发现并自动识别出与疗效相关的特定形态型,不同形态型扩张与生存结局相关。
接着,Shouval博士展示了名为“Inflamex”的无监督学习模型如何从患者基线实验室和细胞因子数据中发现与不良预后相关的“炎症状态”,该状态与肿瘤负荷无关,但与CAR-T细胞扩增减少及免疫抑制微环境有关,揭示了潜在的可干预机制。在毒性预测方面,其团队通过“Cartography”项目对数千名患者的每日临床数据进行了精细标注与无监督时间聚类,识别出高、中、低毒性原型,且高毒性原型患者具有独特的基线蛋白质组学特征(如高干扰素-γ),并构建了循环神经网络模型以预测次日毒性风险。
最后,他介绍了利用多模态数据(临床、实验室、细胞因子、超声心动图、心电图、CT放射组学等)构建预测模型,用于早期识别CAR-T治疗后心血管毒性的工作,验证了多模态融合提升预测准确度的价值。Shouval博士总结,理解细胞治疗结局需综合考虑动态的宿主-肿瘤-免疫特征,而AI在揭示生物学规律与支持临床预测方面潜力巨大。
04
工程视角下的AI未来:数据协同与跨领域迁移
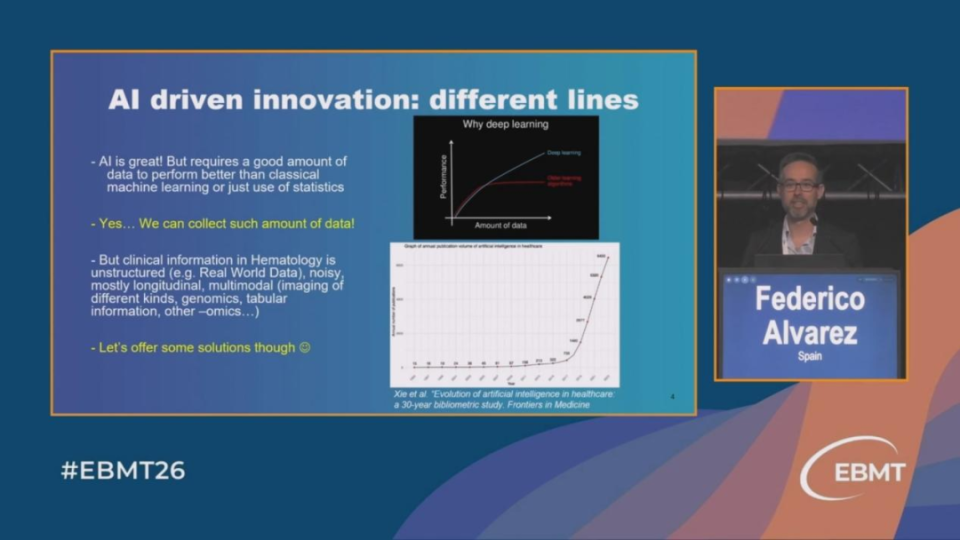
来自马德里的Federico Alvarez博士以工程师的视角,描绘了AI在血液学领域更广阔的未来图景。他指出,AI的成功依赖于大量高质量数据,但医疗数据存在非结构化、纵向、多模态等特点。当前,生成式AI的兴起为解决这些挑战提供了新思路,如用于数据增强、试验设计自动化及监管数据转换等。
Alvarez博士强调了几项关键技术趋势:一是联合式学习,多个中心的医疗数据能在不离开原站点的情况下联合训练AI模型,有效解决数据孤岛与隐私顾虑,释放罕见病领域大数据的力量。二是多模态学习,利用变分自编码器、Transformer等深度学习技术,将基因组学、影像组学、代谢组学等不同模态的数据映射到统一的特征空间,实现有效整合与协同分析。三是基础模型与迁移学习,借鉴在自然语言处理等领域预训练的大型模型,将其适配应用于医疗场景,如利用影像基础模型助力PET/CT在多发性骨髓瘤中的预后评估,实现高效、数据节省的生物标志物开发。他介绍了Genomed4All、Synthema等项目在这些方向上的实践,致力于在MDS、多发性骨髓瘤、镰状细胞病等疾病中整合多组学数据、生成合成数据,并探索药物重定位。
05
深度讨论:从研究到临床的“最后一公里”


精彩演讲结束后,主持人Rafael Duarte与Isabel Sanchez-Ortega引导了深入的小组讨论。现场与会专家质疑了当前AI工具在常规实践中的可用性,而演讲者们坦言,除诊断领域(如AI核型分析)已有七年以上临床使用经验外,大多数预测模型仍处于研究阶段,原因在于治疗领域变化迅速,模型易过时。Roni Shouval认为,这些模型的核心贡献在于揭示了生物学机制,引导了新的治疗靶点。Matteo Della Porta则指出,缺乏充分临床验证是监管转化的主要障碍,呼吁临床界通过“数字试验”主动为AI工具提供效用证据。
关于合成数据,与会者重点关注了其可信度验证及历史数据偏倚等问题。Della Porta回应称,必须建立基于统计学的透明评估框架来验证生成过程,而合成数据的“条件生成”特性可根据需求匹配特定队列特征,在一定程度上缓解偏倚。针对年轻医生如何参与AI变革,Claudia Haferlach建议积极寻求跨学科合作,参加如欧洲血液学学校(ESH)举办的专题研讨会,以临床问题驱动AI应用。
最后,讨论中还触及了数据共享、EBMT登记库价值等现实问题。专家们一致认为,传统登记库数据有其固有局限,未来需通过与电子病历链接、整合基因组数据等方式丰富信息维度,同时合成数据可作为填补缺失值、优化登记库质量的工具。联合式学习与多中心协作是突破数据瓶颈、实现AI价值的关键。
总结
本次EBMT全体会议全景式地展现了人工智能在血液学与细胞治疗领域从诊断革新到治疗优化、从数据困境破解到临床试验范式变革的深刻影响。AI已不再仅仅是效率提升的工具,更成为揭示疾病复杂机制、实现个体化治疗预测,以及突破传统研究方法瓶颈的核心驱动力。然而,会议也清醒地揭示了将AI从研究论文转化为可信赖的临床常规工具所面临的严峻挑战:模型的稳健验证、可解释性、伦理与监管框架的建立,以及临床医生与AI技术的深度融合培训,构成了“最后一公里”的复合难题。
未来,学科的进步必将依赖于临床医学、数据科学、生物信息学与工程学的深度交叉协作。通过构建高质量、标准化的数据基础设施,开发透明、可解释、经过前瞻性验证的AI模型,并建立跨学科的培训与协作生态,人工智能才能真正实现其承诺,将血液学、移植与细胞治疗带入一个以数据驱动、精准预测和高度个性化为特征的崭新时代,最终惠及每一位患者。